Our users at Retro-CI alerted us to a bug that needed an urgent release from us to patch.
The bug originally appeared as though when a user accepted CD3 and CD4 results automatically imported from an analyzer, only the CD4 results then appeared in the biological validation screen. Normally all accepted results should then appear in the validation screen after acceptance by a technician. When the user checked the manual results entry screen, the already accepted CD3 results appeared on that screen ready for results entry, but with the imported value already entered. To solve this problem and get the results to show up in validation, it initially appeared that the user would need to select a checkbox to flag as "analyzer result". Once this checkbox was checked for this rogue result, the result suddenly appeared on the biological validation screen. Since checking this box led to the result suddenly appearing in the proper spot, the assumption that this was the behavior that fixed the problem with the result.
However, sometimes when an outcome is the desired result, it is easy to believe the last action taken caused that result -- like superstitious beliefs -- so you repeat that action again and again hoping for the same outcome. Like throwing spilled salt over your shoulder to make good things happen in life, users will continue to interact with software in a certain manner believing that it makes the software work in a certain way. In troubleshooting bugs, it's also easy to focus on some user action as the fix (or the cause) of some outcome and sometimes make it difficult to determine the true issue at hand.
In this case, we knew that the fact the result got stuck in results entry rather than moving to validation step had something to do with the "state" of the test result. As samples move through the workflow in OpenELIS, the software keeps track of the status or state of the sample, the tests ordered, and the results of those tests in the workflow. So when a test result first enters the system, it appears as a state of "not accepted by technician". After the technician accepts the analyzer import of the results, those results change to a state of "accepted by technician". Only those results with a state of "accepted by technician" will appear in validation.
We could see that once a technician accepted the result, the state for the CD3 results did not change and still showed "not accepted by technician" - even though we knew for a fact that it was. We knew from the bug report that users believed that the actual clicking of this checkbox was what was changing the state to "accepted" so it would move into validation. But after some troubleshooting, we realized that it was actually the changing of the record within the results entry screen that triggered the state change. That could include checking the checkbox, changing the results value, or anything on that results entry screen would cause the record to be updated upon saving and thus trigger the state change. So it was superstitious behavior because the checkbox really had nothing to do with the state change.
As an additional note of the troubleshooting, we realized it wasn't only with CD3 results, but users only saw this because CD3 was always 1st on the list of the results and it was this that was the actual bug. Any result that was 1st on the list of results would not change state, so we fixed this as well.
And with that, we released OpenELIS\Global v2.7.3.

Showing posts with label bugs. Show all posts
Showing posts with label bugs. Show all posts
Tuesday, September 25, 2012
Wednesday, August 15, 2012
Improving Error Messages to the User
Jan talked about the work we've been doing to better isolate the causes of the "Grey Screen of Death" — the error page that appears when there's a problem with the OpenELIS system. She mentioned the frustration with the vague "it's not your fault" language that appeared on the GSOD page.
Old "GSOD" error page in French:

Old "GSOD" error page in English:

The original intent was to assure users, particularly those without a lot of experience with such systems, that they didn't "cause" this problem hence the "it's not your fault" language.
While that sounds good in theory, we learned that what's most important is to figure out what went wrong and get it fixed. By providing more context when someone sees a "GSOD" error, we can get better feedback on what happened. This can make the process of auditing what went wrong much easier for the on-site system administrator and, ultimately, the development team.
To that end, we've redesigned the "GSOD" page to grab details about the user's browser, path through the system, etc. We also tried to include clear action steps that are general enough to make sense at any lab that uses OpenELIS. We also made it a little more appealing to the eyes:
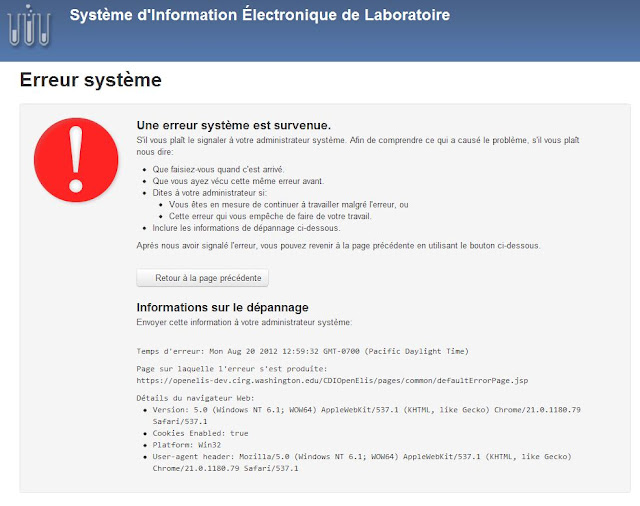
First off, you'll see that the error message now keeps the OpenELIS "header"—that section at the top of the page with the logo and the blue background. Compared to the old version that just had the gray error box on a blank page, this version may be a little less jarring to the user.
The top section lists steps that the user should take to help report this problem. At the bottom is system information that can easily be copy and pasted into an email or printed. Not shown in this screenshot is the listing for the previous page the user was on before they saw this error—this can be particularly helpful in understanding what happened.
This is a start, but we're doing more work to make the (hopefully infrequent) encounter with system errors more efficient. We'll be adding a separate 404 "Page not found" error message that will have specific reporting instructions. We're also thinking of what, if any, part of the server error log could be included. While that might be helpful, security and privacy remain paramount - we don't want to expose any details that could be used to attack the system if an unauthorized user gained access.
If you have any questions or comments, let us know. And if you think of a better name for this new friendlier, more helpful page than "Grey Screen of Death," we'd be happy to using a term that's a little less morbid.
Old "GSOD" error page in French:

Old "GSOD" error page in English:

While that sounds good in theory, we learned that what's most important is to figure out what went wrong and get it fixed. By providing more context when someone sees a "GSOD" error, we can get better feedback on what happened. This can make the process of auditing what went wrong much easier for the on-site system administrator and, ultimately, the development team.
To that end, we've redesigned the "GSOD" page to grab details about the user's browser, path through the system, etc. We also tried to include clear action steps that are general enough to make sense at any lab that uses OpenELIS. We also made it a little more appealing to the eyes:
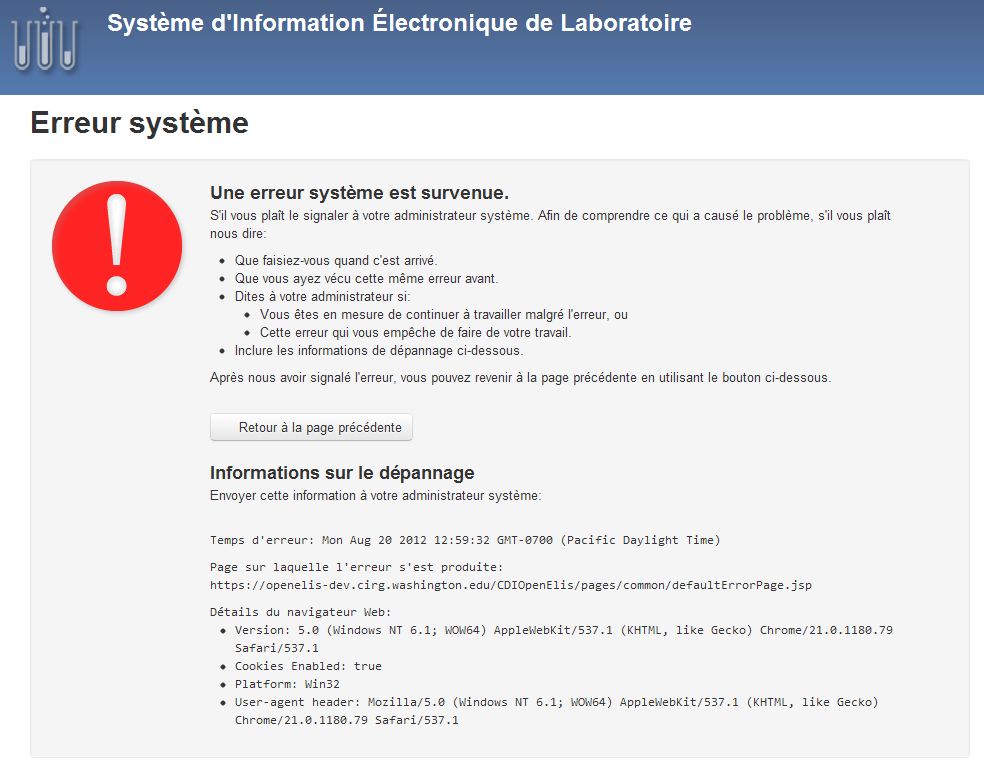
The top section lists steps that the user should take to help report this problem. At the bottom is system information that can easily be copy and pasted into an email or printed. Not shown in this screenshot is the listing for the previous page the user was on before they saw this error—this can be particularly helpful in understanding what happened.
This is a start, but we're doing more work to make the (hopefully infrequent) encounter with system errors more efficient. We'll be adding a separate 404 "Page not found" error message that will have specific reporting instructions. We're also thinking of what, if any, part of the server error log could be included. While that might be helpful, security and privacy remain paramount - we don't want to expose any details that could be used to attack the system if an unauthorized user gained access.
If you have any questions or comments, let us know. And if you think of a better name for this new friendlier, more helpful page than "Grey Screen of Death," we'd be happy to using a term that's a little less morbid.
Friday, August 10, 2012
The Grey Screen of Death
In the previous post I mentioned that our team is focused on fixing a long-standing ever-elusive bug that has consistently been very disruptive to end users (users only see the message "It's not your fault"). One of our implementations is consistently seeing an increase in this message that can only be resolved by stopping the web application and restarting it. Due to the ability of this bug to completely disrupt the entire lab, and up to this point our inability to figure out what was causing this bug, we gave this bug the name of "the grey screen of death" - alluding to a common bug that computer users see when their computer system crashes and all they see is a "blue screen of death" and must restart their systems.
Current Grey Screen of Death message (in french):
 The grey screen of death has been so elusive that up until now our troubleshooting process hasn't been able to determine what actually causes it - asking users what steps they took, looking at the logs, attempting to replicate the bug - none of it made sense or helped us solve it. All we knew was that this error was supposed to appear when there was an uncaught exception in the system (for the technical folks - we put this in place so stack traces never printed to the browser). Theoretically, the user should have never seen it. Unfortunately, in our development priorities, we never found time to improve our error pages to give the user more information to help us help them.
The grey screen of death has been so elusive that up until now our troubleshooting process hasn't been able to determine what actually causes it - asking users what steps they took, looking at the logs, attempting to replicate the bug - none of it made sense or helped us solve it. All we knew was that this error was supposed to appear when there was an uncaught exception in the system (for the technical folks - we put this in place so stack traces never printed to the browser). Theoretically, the user should have never seen it. Unfortunately, in our development priorities, we never found time to improve our error pages to give the user more information to help us help them.
This week we finally found some clues and have put in fixes for what we think is causing the problem. First, we figured out that this error appears for both uncaught exceptions (system errors) and 404 page errors. So we've separated those out to be two different error screens.
For the uncaught exceptions, the problem appears to come from two different workflows:
Current Grey Screen of Death message (in french):

This week we finally found some clues and have put in fixes for what we think is causing the problem. First, we figured out that this error appears for both uncaught exceptions (system errors) and 404 page errors. So we've separated those out to be two different error screens.
For the uncaught exceptions, the problem appears to come from two different workflows:
- Lab test results are automatically imported from an analyzer after a sample was marked non-conforming. In other words, no sample entry was performed in the system but a non-conformity event was entered for the sample. When the results are saved, the user is told that it is successful, but it wasn't. The analyzer result reappeared on the screen.
- Prior to sample entry the analyzer imports of two different sample types are accepted. When the 2nd import is saved, it causes the grey screen of death. This particular workflow puts the application into an unstable state that causes all of the users in the system to experience the grey screen of death until the system is restarted. For the technical folks - This is due to Hibernate not knowing what to do with a transient object that is created when it tries to flush the cache an exception is thrown and the object remains in the cache. The system is unable to remove it from the cache so every Hibernate action continues to cause exceptions.
Along with determining the cause of the bug, our users adamantly told us that they needed better feedback from the screen when they receive any type of error. Simply stating "It's not your fault" only frustrated them because they wanted to know what was happening to the system and how to get help to solve it. So we spent time improving this. I will talk about those improvements in the next post.
Subscribe to:
Posts (Atom)